Chapter 1: Introduction to AWK
By Blogger
· 114 views
Fri, 11 Jul 2025 17:33:37 +0530
If you're a Linux system administrator, you've probably encountered situations where you need to extract specific information from log files, process command output, or manipulate text data.
While tools like grep and sed are useful, there's another much more powerful tool in your arsenal that can handle complex text processing tasks with remarkable ease: AWK.
What is AWK and why should You care about it?
AWK is not just a UNIX command, it is a powerful programming language designed for pattern scanning and data extraction. Named after its creators (Aho, Weinberger, and Kernighan), AWK excels at processing structured text data, making it invaluable for system administrators who regularly work with log files, configuration files, and command output.
Here's why AWK should be in your and every sysadmin's toolkit:
- Built for text processing: AWK automatically splits input into fields and records, making column-based data trivial to work with.
- Pattern-action paradigm: You can easily define what to look for (pattern) and what to do when found (action).
- No compilation needed: Unlike most other programming languages, AWK scripts do not need to be compiled first. AWK scripts run directly and thus making them perfect for quick one-liners and shell integration.
- Handles complex logic: Unlike simple Linux commands, AWK supports variables, arrays, functions, and control structures.
- Available everywhere: Available on virtually every Unix-like system and all Linux distros by default.
AWK vs sed vs grep: When to use which tool
grep, sed and awk all three deal with data processing and that may make you wonder whether you should use sed or grep or AWK.
In my opinion, you should
Use grep when:
- You need to find lines matching a pattern
- Simple text searching and filtering
- Binary yes/no decisions about line content
# Find all SSH login attempts
grep "ssh" /var/log/auth.log
Use sed when:
- You need to perform find-and-replace operations
- Simple text transformations
- Stream editing with minimal logic
# Replace all occurrences of "old" with "new"
sed 's/old/new/g' file.txt
Use AWK when:
- You need to work with columnar data
- Complex pattern matching with actions
- Mathematical operations on data
- Multiple conditions and logic branches
- Generating reports or summaries
# Print username and home directory from /etc/passwd
awk -F: '{print $1, $6}' /etc/passwd
Now that you are a bit more clear about when to use AWK, let's see the basics of AWK command structure.
Basic AWK syntax and structure
AWK follows a simple but powerful syntax:
awk 'pattern { action }' file
- Pattern: Defines when the action should be executed (optional)
- Action: What to do when the pattern matches (optional)
- File: Input file to process (can also read from stdin)
Let's get started with using AWK for some simple but interesting use cases.
Your first AWK Command: Printing specific columns
Let's start with a practical example. Suppose you want to see all users in Linux and their home directories from /etc/passwd file:
awk -F: '{print $1, $6}' /etc/passwd
The output should be something like this:

root /root
daemon /usr/sbin
bin /bin
sys /dev
sync /bin
games /usr/games
...
Let's break this doww:
-F:sets the field separator to colon (since/etc/passwduses colons)$1refers to the first field (username)$6refers to the sixth field (home directory)printoutputs the specified fields
Understanding AWK's automatic field splitting and
AWK automatically splits each input line into fields based on whitespace (i.e. spaces and tabs) by default. Each field is accessible through variables:
$0- The entire line$1- First field$2- Second field$NF- Last field (NF = Number of Fields)$(NF-1)- Second to last field
Let's see it in action by extracting process information from the ps command output.
ps aux | awk '{print $1, $2, $NF}'
This prints the user, process ID, and command for each running process.

NF is one of the several built-in variables
Know built-in variables: Your data processing toolkit
AWK provides several built-in variables that make text processing easier.

FS (Field separator)
By default, AWK uses white space, i.e. tabs and spaces as field separator. With FS, you can define other field separators in your input.
For example, /etc/passwd file contains lines that have values separated by colon : so if you define file separator as : and extract the first column, you'll get the list of the users on the system.
awk -F: '{print $1}' /etc/passwd

You'll get the same result with the following command.
awk 'BEGIN {FS=":"} {print $1}' /etc/passwdMore about BEGIN in later part of this AWK series.
NR (Number of records/lines)
NR keeps track of the current line number. It is helpful when you have to take actions for certain lines in a file.
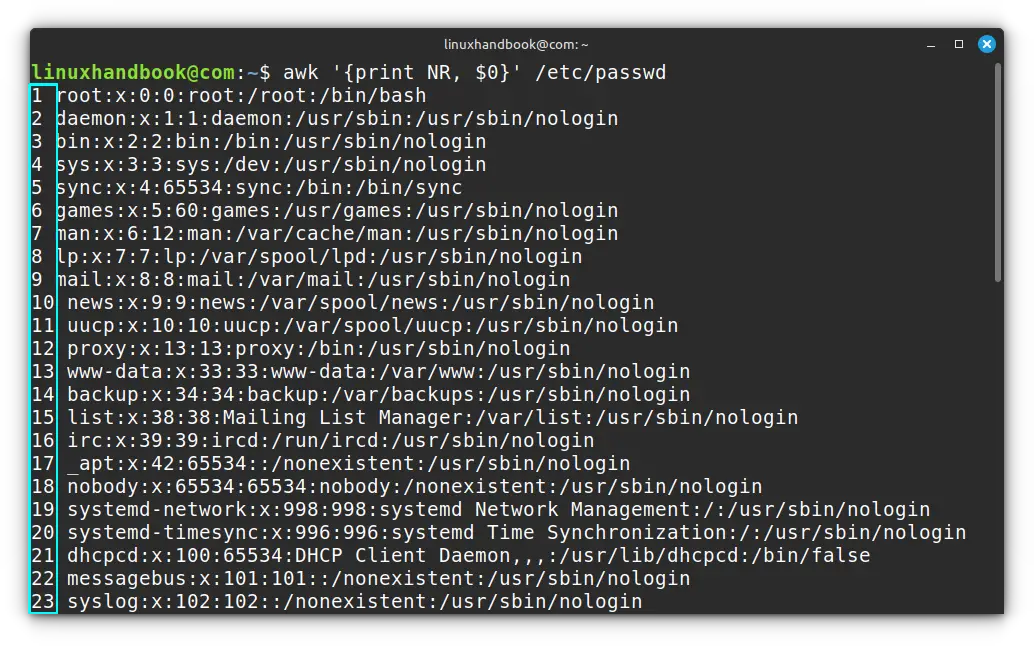
For example, the command below will output the content of the /etc/passwd file but with line numbers attached at the beginning.
awk '{print NR, $0}' /etc/passwd
NF (Number of fields)
NF contains the number of fields in the current record. Which is basically number of columns when separated by FS.
For example, the command below will print exactly 5 fields in each line.
awk -F: 'NF == 5 {print $0}' /etc/passwd

Practical examples for system administrators
Let's see some practical use cases where you can utilize the power of AWK.
Example 1: Analyzing disk usage
The command below shows disk usage percentages and mount points, sorted by usage where as skipping the header line with NR > 1.
df -h | awk 'NR > 1 {print $5, $6}' | sort -nr

Example 2: Finding large files
I know that find command is more popular for this but you can also use AWK to print file sizes and names for files larger than 1MB.
ls -l | awk '$5 > 1000000 {print $5, $NF}'

Example 3: Processing log files
awk '/ERROR/ {print $1, $2, $NF}' /var/log/syslog
This extracts timestamp and error message from log files containing "ERROR".
Example 4: Memory usage summary
Use AWK to calculate and display memory usage percentage.
free -m | awk 'NR==2 {printf "Memory Usage: %.1f%%\n", $3/$2 * 100}'

Pattern matching in AWK works like a smart bouncer - it evaluates conditions and controls access to actions. Master these concepts:It is slightly complicated than the other examples, so let me break it down for you.
Typical free command output looks like this:
total used free shared buff/cache available
Mem: 7974 3052 723 321 4199 4280
Swap: 2048 10 2038
With NR==2 we only take the second line from the above output. $2 (second column) gives total memory and $3 gives used memory.
Next, in printf "Memory Usage: %.1f%%\n", $3/$2 * 100 , the printf command prints formatted output, %.1f%% shows one decimal place, and a % symbol and $3/$2 * 100 calculates memory used as a percentage.
So in the example above, you get the output as Memory Usage: 38.3% where 3052 is ~38.3% of 7974.
You'll learn more on arithmetical operation with AWK later in this series.
🪧 Time to recall
In this introduction, you've learned:
- AWK is a pattern-action language perfect for structured text processing
- It automatically splits input into fields, making columnar data easy to work with
- Built-in variables like NR, NF, and FS provide powerful processing capabilities
- AWK excels where grep and sed fall short: complex data extraction and manipulation
AWK's real power becomes apparent when you need to process data that requires logic, calculations, or complex pattern matching.
In the next part of this series, we'll dive deeper into pattern matching and conditional operations that will transform how you handle text processing tasks.
🏋️ Practice exercises
Try these exercises to reinforce what you've learned:
- Display only usernames from
/etc/passwd - Show the last field of each line in any file
- Print line numbers along with lines containing "root" in
/etc/passwd - Extract process names and their memory usage from
ps auxoutput - Count the number of fields in each line of a file
The solutions involve combining the concepts we've covered: field variables, built-in variables, and basic pattern matching.
In the next tutorial, we'll explore these patterns in much more detail.
Recommended Comments